 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlow Policy Gradients for Robot Control
Feb 02, 2026Likelihood-based policy gradient methods are the dominant approach for training robot control policies from rewards. These methods rely on differentiable action likelihoods, which constrain policy outputs to simple distributions like Gaussians. In this work, we show how flow matching policy gradients -- a recent framework that bypasses likelihood computation -- can be made effective for training and fine-tuning more expressive policies in challenging robot control settings. We introduce an improved objective that enables success in legged locomotion, humanoid motion tracking, and manipulation tasks, as well as robust sim-to-real transfer on two humanoid robots. We then present ablations and analysis on training dynamics. Results show how policies can exploit the flow representation for exploration when training from scratch, as well as improved fine-tuning robustness over baselines.
Viser: Imperative, Web-based 3D Visualization in Python
Jul 30, 2025We present Viser, a 3D visualization library for computer vision and robotics. Viser aims to bring easy and extensible 3D visualization to Python: we provide a comprehensive set of 3D scene and 2D GUI primitives, which can be used independently with minimal setup or composed to build specialized interfaces. This technical report describes Viser's features, interface, and implementation. Key design choices include an imperative-style API and a web-based viewer, which improve compatibility with modern programming patterns and workflows.
Flow Matching Policy Gradients
Jul 28, 2025Flow-based generative models, including diffusion models, excel at modeling continuous distributions in high-dimensional spaces. In this work, we introduce Flow Policy Optimization (FPO), a simple on-policy reinforcement learning algorithm that brings flow matching into the policy gradient framework. FPO casts policy optimization as maximizing an advantage-weighted ratio computed from the conditional flow matching loss, in a manner compatible with the popular PPO-clip framework. It sidesteps the need for exact likelihood computation while preserving the generative capabilities of flow-based models. Unlike prior approaches for diffusion-based reinforcement learning that bind training to a specific sampling method, FPO is agnostic to the choice of diffusion or flow integration at both training and inference time. We show that FPO can train diffusion-style policies from scratch in a variety of continuous control tasks. We find that flow-based models can capture multimodal action distributions and achieve higher performance than Gaussian policies, particularly in under-conditioned settings.
Visual Imitation Enables Contextual Humanoid Control
May 07, 2025
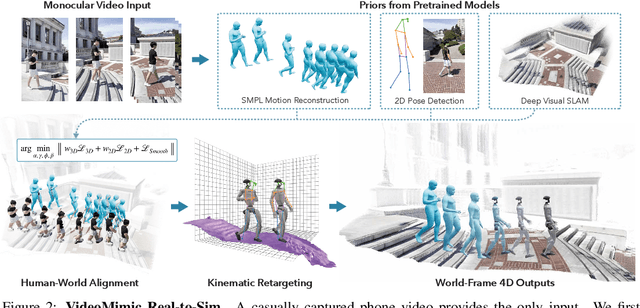


How can we teach humanoids to climb staircases and sit on chairs using the surrounding environment context? Arguably, the simplest way is to just show them-casually capture a human motion video and feed it to humanoids. We introduce VIDEOMIMIC, a real-to-sim-to-real pipeline that mines everyday videos, jointly reconstructs the humans and the environment, and produces whole-body control policies for humanoid robots that perform the corresponding skills. We demonstrate the results of our pipeline on real humanoid robots, showing robust, repeatable contextual control such as staircase ascents and descents, sitting and standing from chairs and benches, as well as other dynamic whole-body skills-all from a single policy, conditioned on the environment and global root commands. VIDEOMIMIC offers a scalable path towards teaching humanoids to operate in diverse real-world environments.
PyRoki: A Modular Toolkit for Robot Kinematic Optimization
May 06, 2025



Robot motion can have many goals. Depending on the task, we might optimize for pose error, speed, collision, or similarity to a human demonstration. Motivated by this, we present PyRoki: a modular, extensible, and cross-platform toolkit for solving kinematic optimization problems. PyRoki couples an interface for specifying kinematic variables and costs with an efficient nonlinear least squares optimizer. Unlike existing tools, it is also cross-platform: optimization runs natively on CPU, GPU, and TPU. In this paper, we present (i) the design and implementation of PyRoki, (ii) motion retargeting and planning case studies that highlight the advantages of PyRoki's modularity, and (iii) optimization benchmarking, where PyRoki can be 1.4-1.7x faster and converges to lower errors than cuRobo, an existing GPU-accelerated inverse kinematics library.
Reconstructing People, Places, and Cameras
Dec 23, 2024



We present "Humans and Structure from Motion" (HSfM), a method for jointly reconstructing multiple human meshes, scene point clouds, and camera parameters in a metric world coordinate system from a sparse set of uncalibrated multi-view images featuring people. Our approach combines data-driven scene reconstruction with the traditional Structure-from-Motion (SfM) framework to achieve more accurate scene reconstruction and camera estimation, while simultaneously recovering human meshes. In contrast to existing scene reconstruction and SfM methods that lack metric scale information, our method estimates approximate metric scale by leveraging a human statistical model. Furthermore, it reconstructs multiple human meshes within the same world coordinate system alongside the scene point cloud, effectively capturing spatial relationships among individuals and their positions in the environment. We initialize the reconstruction of humans, scenes, and cameras using robust foundational models and jointly optimize these elements. This joint optimization synergistically improves the accuracy of each component. We compare our method to existing approaches on two challenging benchmarks, EgoHumans and EgoExo4D, demonstrating significant improvements in human localization accuracy within the world coordinate frame (reducing error from 3.51m to 1.04m in EgoHumans and from 2.9m to 0.56m in EgoExo4D). Notably, our results show that incorporating human data into the SfM pipeline improves camera pose estimation (e.g., increasing RRA@15 by 20.3% on EgoHumans). Additionally, qualitative results show that our approach improves overall scene reconstruction quality. Our code is available at: muelea.github.io/hsfm.
FineControlNet: Fine-level Text Control for Image Generation with Spatially Aligned Text Control Injection
Dec 14, 2023Recently introduced ControlNet has the ability to steer the text-driven image generation process with geometric input such as human 2D pose, or edge features. While ControlNet provides control over the geometric form of the instances in the generated image, it lacks the capability to dictate the visual appearance of each instance. We present FineControlNet to provide fine control over each instance's appearance while maintaining the precise pose control capability. Specifically, we develop and demonstrate FineControlNet with geometric control via human pose images and appearance control via instance-level text prompts. The spatial alignment of instance-specific text prompts and 2D poses in latent space enables the fine control capabilities of FineControlNet. We evaluate the performance of FineControlNet with rigorous comparison against state-of-the-art pose-conditioned text-to-image diffusion models. FineControlNet achieves superior performance in generating images that follow the user-provided instance-specific text prompts and poses compared with existing methods. Project webpage: https://samsunglabs.github.io/FineControlNet-project-page
HandNeRF: Learning to Reconstruct Hand-Object Interaction Scene from a Single RGB Image
Sep 14, 2023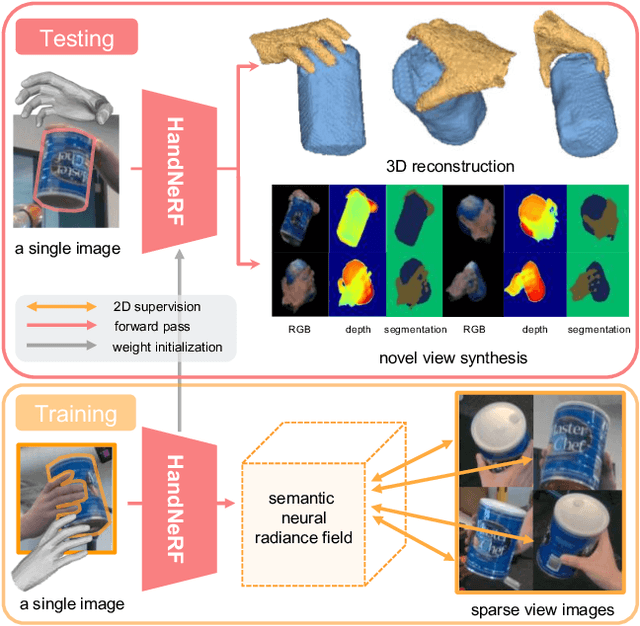



This paper presents a method to learn hand-object interaction prior for reconstructing a 3D hand-object scene from a single RGB image. The inference as well as training-data generation for 3D hand-object scene reconstruction is challenging due to the depth ambiguity of a single image and occlusions by the hand and object. We turn this challenge into an opportunity by utilizing the hand shape to constrain the possible relative configuration of the hand and object geometry. We design a generalizable implicit function, HandNeRF, that explicitly encodes the correlation of the 3D hand shape features and 2D object features to predict the hand and object scene geometry. With experiments on real-world datasets, we show that HandNeRF is able to reconstruct hand-object scenes of novel grasp configurations more accurately than comparable methods. Moreover, we demonstrate that object reconstruction from HandNeRF ensures more accurate execution of a downstream task, such as grasping for robotic hand-over.
Three Recipes for Better 3D Pseudo-GTs of 3D Human Mesh Estimation in the Wild
Apr 10, 2023



Recovering 3D human mesh in the wild is greatly challenging as in-the-wild (ITW) datasets provide only 2D pose ground truths (GTs). Recently, 3D pseudo-GTs have been widely used to train 3D human mesh estimation networks as the 3D pseudo-GTs enable 3D mesh supervision when training the networks on ITW datasets. However, despite the great potential of the 3D pseudo-GTs, there has been no extensive analysis that investigates which factors are important to make more beneficial 3D pseudo-GTs. In this paper, we provide three recipes to obtain highly beneficial 3D pseudo-GTs of ITW datasets. The main challenge is that only 2D-based weak supervision is allowed when obtaining the 3D pseudo-GTs. Each of our three recipes addresses the challenge in each aspect: depth ambiguity, sub-optimality of weak supervision, and implausible articulation. Experimental results show that simply re-training state-of-the-art networks with our new 3D pseudo-GTs elevates their performance to the next level without bells and whistles. The 3D pseudo-GT is publicly available in https://github.com/mks0601/NeuralAnnot_RELEASE.
Rethinking Self-Supervised Visual Representation Learning in Pre-training for 3D Human Pose and Shape Estimation
Mar 09, 2023



Recently, a few self-supervised representation learning (SSL) methods have outperformed the ImageNet classification pre-training for vision tasks such as object detection. However, its effects on 3D human body pose and shape estimation (3DHPSE) are open to question, whose target is fixed to a unique class, the human, and has an inherent task gap with SSL. We empirically study and analyze the effects of SSL and further compare it with other pre-training alternatives for 3DHPSE. The alternatives are 2D annotation-based pre-training and synthetic data pre-training, which share the motivation of SSL that aims to reduce the labeling cost. They have been widely utilized as a source of weak-supervision or fine-tuning, but have not been remarked as a pre-training source. SSL methods underperform the conventional ImageNet classification pre-training on multiple 3DHPSE benchmarks by 7.7% on average. In contrast, despite a much less amount of pre-training data, the 2D annotation-based pre-training improves accuracy on all benchmarks and shows faster convergence during fine-tuning. Our observations challenge the naive application of the current SSL pre-training to 3DHPSE and relight the value of other data types in the pre-training aspect.